Google’s robots.txt tester inside Search Console will report a URL as “Blocked” while the same platform’s index coverage report simultaneously shows that identical URL as “Indexed, not submitted in sitemap.” Two tools, same platform, producing opposite conclusions about whether a page belongs in Google’s index. The cause, in nearly every case we’ve diagnosed for Australian businesses, traces back to a single architectural mistake: the site’s robots.txt and its meta noindex directives are issuing contradictory instructions to the same crawler.
This conflict has a documented origin point, a well-understood mechanism, and a fix that takes about fifteen minutes once you know where to look. But it persists across thousands of sites because the two systems were designed for different purposes and operate at different stages of the crawl cycle.
The Disallow-Plus-Noindex Trap
Here’s the core problem. A developer adds a Disallow rule in robots.txt to block Googlebot from crawling a directory—say, /staging/ or /internal/. Separately, the pages in that directory carry a meta noindex tag in their HTML head section. The developer assumes both layers of protection are active.
They’re not. Google’s documentation is explicit: to read a meta noindex directive, Googlebot must first crawl the page and access its HTML. If robots.txt blocks the crawl, Googlebot never reaches the head section. It never sees the noindex tag. The directive might as well not exist.
So what happens to the URL? If other sites link to it, or if it appeared in a sitemap at some point, Google may index it anyway, using whatever anchor text and context it can scrape from external signals. You end up with a thin, contentless listing in search results: a URL with a title guessed from inbound links and no snippet, because Google has no page content to work with.
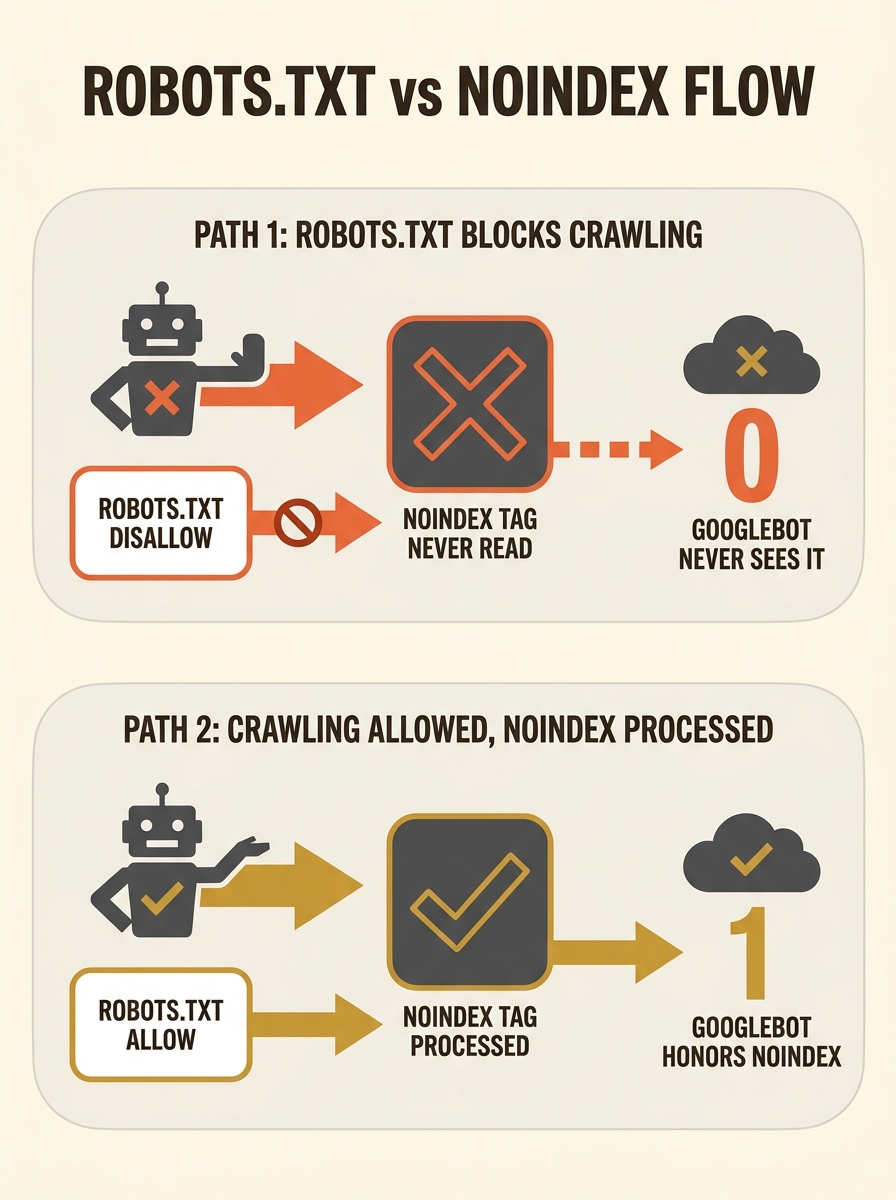
This is the most common robots.txt conflict pattern we encounter during a technical SEO audit, and it’s particularly prevalent on sites that went through a redesign or platform migration without reconciling their crawling indexing rules. We’ve written about the broader category of crawling rule conflicts and how to untangle them, but this specific Disallow-plus-noindex collision deserves its own dissection because of how cleanly it illustrates the problem.
Google’s 2019 Deprecation and the Sites It Broke
Before September 2019, there was a grey-area workaround. Some webmasters placed noindex directives directly inside their robots.txt files, formatted like any other rule. Google’s crawler unofficially respected this for years. It was never part of the formal robots.txt specification, but it worked, and enough SEO guides recommended it that thousands of sites relied on it as their primary deindexing mechanism.
Then Google deprecated support entirely. The announcement was clear: noindex in robots.txt would no longer be processed. The reasoning was straightforward. Robots.txt controls crawling, not indexing. Meta robots tags and X-Robots-Tag HTTP headers control indexing. Mixing the two in a single file created ambiguity that the formalisation of the Robots Exclusion Protocol as RFC 9309 in 2022 was specifically designed to eliminate.
The fallout was measurable. Sites that had used robots.txt noindex as their only deindexing mechanism suddenly found previously hidden pages surfacing in search results. Staging environments, duplicate product pages, internal tools, all appearing in Google with no meta noindex directives in their HTML to fall back on.
Warning: If your site was set up before 2020, check whether any legacy robots.txt noindex rules are still present. They’ve been doing nothing for years, and the pages they were meant to suppress may be sitting in Google’s index right now.
For e-commerce SEO in particular, this caused real damage. Online stores routinely generate thousands of faceted navigation pages, filtered product listings, and session-based URLs. Many had relied on robots.txt to manage these at scale. When the noindex-in-robots.txt shortcut disappeared, those pages flooded the index with near-duplicate content.
What a Crawl Log Reveals When Both Systems Disagree
The conflict doesn’t announce itself through a red warning in Search Console. There’s no alert saying “your robots.txt and meta tags disagree.” You have to look for the symptoms, and the looking requires comparing two separate data sets that most audit tools present independently.
Run a crawl with Screaming Frog or Sitebulb and filter for pages carrying a meta noindex directive. Export that list. Then cross-reference it against your robots.txt Disallow rules. Any URL that appears on both lists has the conflict: it’s blocked from crawling AND tagged with noindex, meaning the noindex is invisible to search engines because the bot never gets close enough to read it.
The second diagnostic is simpler. In Search Console’s Pages report, look for URLs with the status “Blocked by robots.txt” that also appear under “Indexed, though blocked by robots.txt.” That second status is Google telling you it found the URL through external signals and indexed it despite being unable to crawl it. If you intended those pages to be deindexed, your meta noindex directives are failing silently because the robots.txt block takes precedence in the crawl sequence.
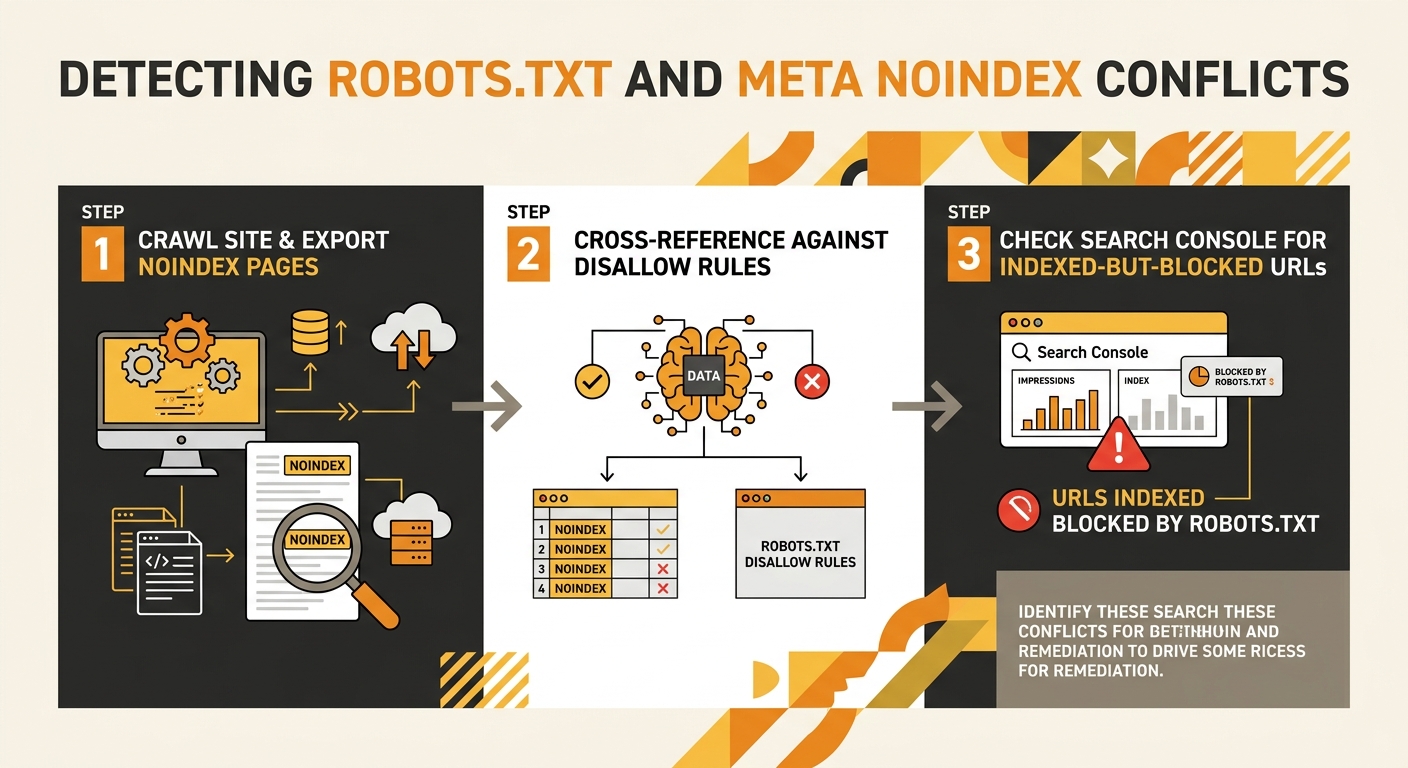
A thorough URL structure audit will catch most of these, but you need to specifically look for the overlap. Standard crawl reports show robots.txt blocks and noindex pages as separate line items. The conflict only becomes visible when you compare the two lists against each other.
The conflict only becomes visible when you compare the two lists against each other. Standard crawl reports treat robots.txt blocks and noindex pages as separate issues.
As one Stack Overflow discussion on this exact scenario explains, the confusion arises because developers assume one file overrides the other. In reality, they operate at different stages: robots.txt gates whether the crawler visits at all, and meta robots tags instruct the crawler once it arrives. If the gate is closed, the instructions inside are never delivered.
AI Crawlers Compounded the Overlap
The introduction of AI-specific user agents has added new dimensions to robots.txt conflicts. Google-Extended (for Gemini and Vertex AI), GPTBot (OpenAI), and CCBot (Common Crawl, used by many AI training pipelines) each have their own robots.txt behaviour. A May 2025 study found that 60% of reputable news sites block at least one AI bot via robots.txt, compared to only 9.1% of misinformation sites.
For Australian businesses, the practical question is whether your robots.txt rules account for these crawlers individually. If you’ve added Disallow rules for GPTBot or Google-Extended but your meta noindex directives were meant to handle indexing decisions, you may have created a new generation of the same conflict. The AI crawler can’t see your page-level instructions because you’ve blocked it at the front door.
We’ve covered the gap between standard technical audits and AI crawler requirements elsewhere, and this robots.txt conflict is one of the most concrete examples of that gap in practice. Your crawling indexing rules need to account for each bot individually, because a Disallow targeting Googlebot doesn’t apply to GPTBot, and vice versa.
The Incremys 2026 technical audit guide flags the same risk, noting that overly broad Disallow rules or a forgotten Disallow: / can cut off crawling for an entire strategic directory. When you’re managing rules for five or six different bot families, the odds of an accidental broad block increase proportionally.
The Directive Hierarchy That Actually Governs Googlebot
The resolution comes down to understanding which directive wins when multiple instructions exist for the same URL. Google’s behaviour follows a clear hierarchy, and once you internalise it, the conflicts become predictable and preventable.
Robots.txt is evaluated first. If it blocks crawling for a given user agent, nothing on the page matters for that bot. The crawler turns away before loading any HTML. This makes Disallow, in practical terms, the highest-priority directive, because it pre-empts everything that follows.
If crawling is allowed, meta robots tags in the HTML head are processed next. A noindex directive here prevents the page from appearing in search results, even if the page is fully crawlable and listed in your XML sitemap. The X-Robots-Tag HTTP header works identically to the meta tag but applies to non-HTML files like PDFs and images.
Canonical tags introduce a third layer. If a page carries both a noindex meta tag and a canonical pointing to a different URL, Google may follow the canonical instead of respecting the noindex. This is a documented edge case that the debugging pyramid for diagnosing ranking drops specifically accounts for, because it generates baffling results in Search Console where pages you’ve marked noindex keep appearing.
The fix for most robots.txt conflicts is conceptually simple: use robots.txt exclusively for crawl management, and use meta noindex directives or X-Robots-Tag exclusively for index management. Don’t layer both on the same URL expecting them to reinforce each other. If you want a page deindexed, it must remain crawlable so the bot can read the noindex instruction. If you want a page uncrawled to save crawl budget, accept that you’re giving up direct control over whether it appears in search results.
For sites with thousands of pages where managing individual meta tags feels impractical, the X-Robots-Tag header is the better tool. It can be configured at the server level for entire directories without touching page templates, and it works on file types that can’t contain HTML meta tags. The conflict surface area drops close to zero because you’re keeping crawl directives and indexing directives in their proper lanes.
The sites that keep running into this problem are the ones treating robots.txt and meta robots as interchangeable tools for the same job. They govern different stages of the same process. Deploy both against the same URL with the assumption they’ll reinforce each other, and you get the silent failure that started this whole dissection: a page blocked from crawling and tagged for deindexing, sitting in Google’s search results based on nothing but a stale backlink and an anchor text guess, with no mechanism for any search engine to discover the noindex tag you carefully placed in its HTML.