
Title tag compliance across Australian business websites sits at 99%, HTTPS adoption exceeds 91%, and viewport meta tags are near-universal, according to 2026 industry analysis from DesignBox. That near-total adoption has made properly formed HTML the least interesting factor in search rankings. The gap between SMEs that rank and those that don’t lives inside the content, length, and intent-matching of their meta tags.
TL;DR: Every Australian SME has technically valid meta tags. The ranking difference comes from title tag length (40–60 characters delivers 33.3% higher CTR), meta description wording that matches search intent, structured data that avoids silent validation failures, and crawling directives that don’t cancel each other out.
Title Tags Are a Ranking Signal, But Their Length and Wording Determine the Outcome
Google’s John Mueller has confirmed that title tags remain a direct ranking factor. “Having a title tag” and “having an optimised title tag” are different problems, though. The first is a checkbox. The second requires understanding character limits, keyword placement, and user psychology.
Backlinko’s analysis of 4 million Google search results found that pages with title tags between 40 and 60 characters have a 33.3% higher click-through rate than those outside that range. That’s a significant spread for something most site owners treat as an afterthought.
Title tag optimisation in Australia follows the same principles as anywhere else, with one local wrinkle: geographic qualifiers eat into your character budget. “Emergency Plumber Melbourne CBD” is already 32 characters before you’ve said anything about what makes you different. You need to front-load the primary keyword, keep the total under 60 characters, and still communicate enough value to earn the click.
Straight North’s 2026 optimisation guide reports that well-matched title tags and meta descriptions can boost click-through rates by 10% to 30%, depending on how closely they align with the searcher’s actual intent. The keyword “emergency plumber” in a title tag doesn’t help if the page content is about bathroom renovations.

Supple Digital lists optimised meta tags as one of the three most important on-page SEO factors, alongside high-quality content and user experience. The takeaway for meta tags technical SEO is straightforward: the tag needs to exist, needs to be the right length, needs to contain the right keyword, and needs to promise something the page actually delivers.
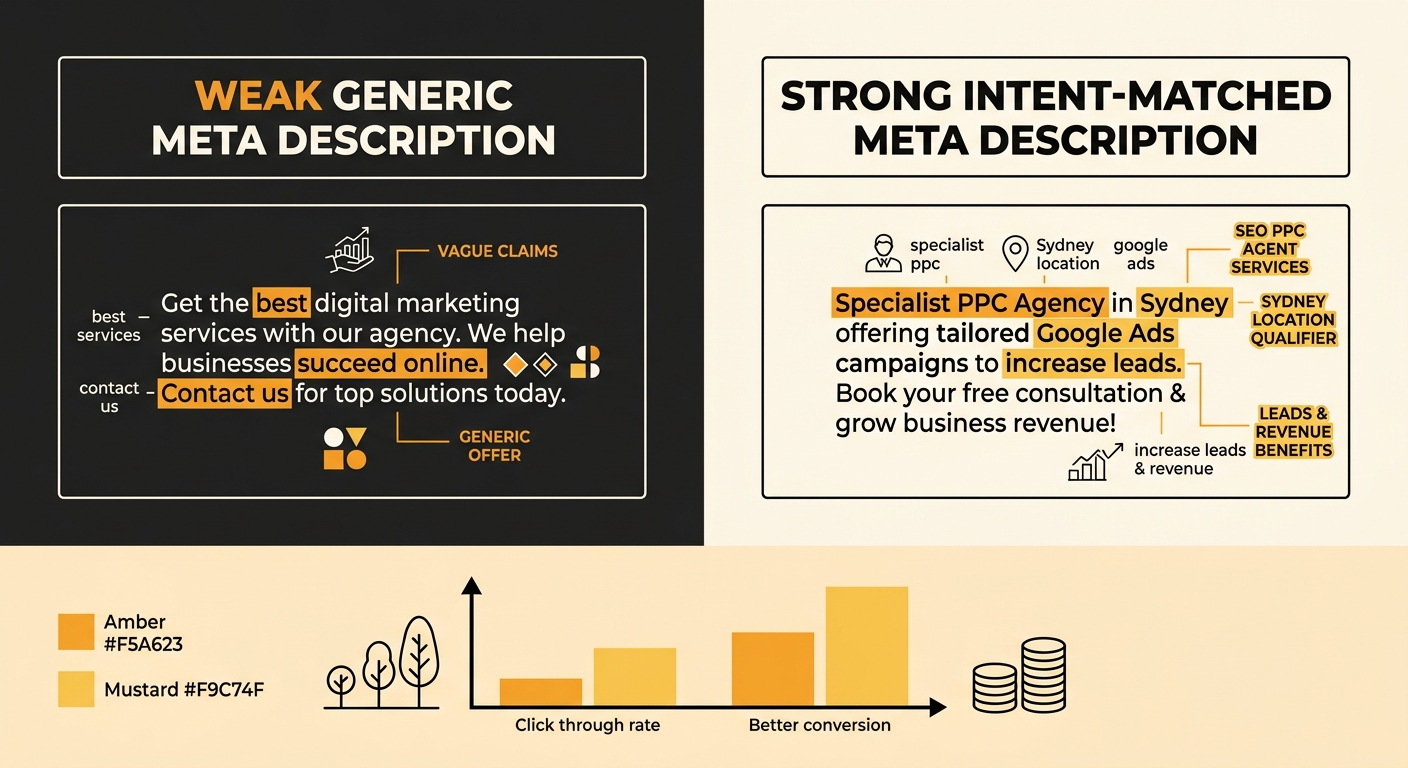
Meta Descriptions Don’t Rank You, But They Decide Who Clicks
Why do meta description click-through rates matter if Google has repeatedly said the meta description isn’t a ranking factor? Because CTR is a behavioural signal that feeds back into rankings indirectly. A page sitting in position 4 that gets clicked more often than position 2 sends data Google doesn’t ignore.
The ideal meta description length lands between 120 and 160 characters, according to Moz’s meta description guide. Yoast puts the figure at roughly 155 characters. Australian agency DigiFix narrows it to 150–160 characters. The consensus is tight: stay in the 120–160 range, and write descriptions that address the searcher’s problem rather than describe your business.
Here’s where Australian SMEs consistently lose ground. The default meta description on most small business sites reads like a company bio: “We are a family-owned business providing quality services since 2003.” That tells Google nothing about what the page answers, and it gives the searcher zero reason to click over the competitor whose description says “Same-day blocked drain repair in Sydney’s Inner West, fixed-price quotes, no call-out fee.”
The best descriptions function as tiny ad copies. They name the specific service, include a geographic qualifier where relevant, and contain a concrete benefit: price, speed, or availability. MSEDP’s research on organic CTR confirms that tailoring title tags and meta descriptions to clearly reflect user intent helps users know immediately whether the content matches their search.
A page in position 4 that gets clicked more often than position 2 sends data Google doesn’t ignore.
For businesses running product-page optimisation on an online store, this gets more complex. Product pages need meta descriptions that include the product name, a key differentiator, and enough specificity that Google doesn’t replace your description with a random page excerpt. Google substitutes meta descriptions roughly 60–70% of the time when it thinks it can generate a better snippet.
Structured Data That Passes Validation Can Still Fail in Search Console
Valid schema markup and functional schema markup are two different things. Screaming Frog’s structured data validation checks whether types and properties exist against the Schema.org vocabulary. Passing that check doesn’t mean Google will generate a rich result.
Structured data validation failures fall into three common patterns:
- Misplaced markup: JSON-LD blocks placed inside the wrong section of the HTML, or injected by plugins that conflict with theme-level schema. Infidigit’s analysis confirms that adding schema in the wrong HTML section causes parsing errors even when the code is syntactically correct.
- Missing required properties: A LocalBusiness schema might validate against Schema.org’s vocabulary but still fail Google’s Rich Results Test because it’s missing the image property. Image requirements are the single most commonly forgotten element, according to debugging patterns documented by Jasmine Directory’s structured data troubleshooting guide.
- Conflicting data: When the structured data says business hours are 9–5 but the page content says 8–6, Google downgrades trust in the markup. This is especially common for multi-location businesses that template their schema without updating location-specific details.
We’ve covered why technically valid schema often doesn’t produce rich results in detail before. The short version: Google applies a stricter standard than Schema.org’s validator, and the gap between those two standards is where most SME structured data silently fails.
If your site architecture creates additional complexity through multiple service pages, location pages, and blog content all carrying different schema types, a broader technical SEO audit of your site structure usually surfaces schema conflicts that page-level checks miss entirely.
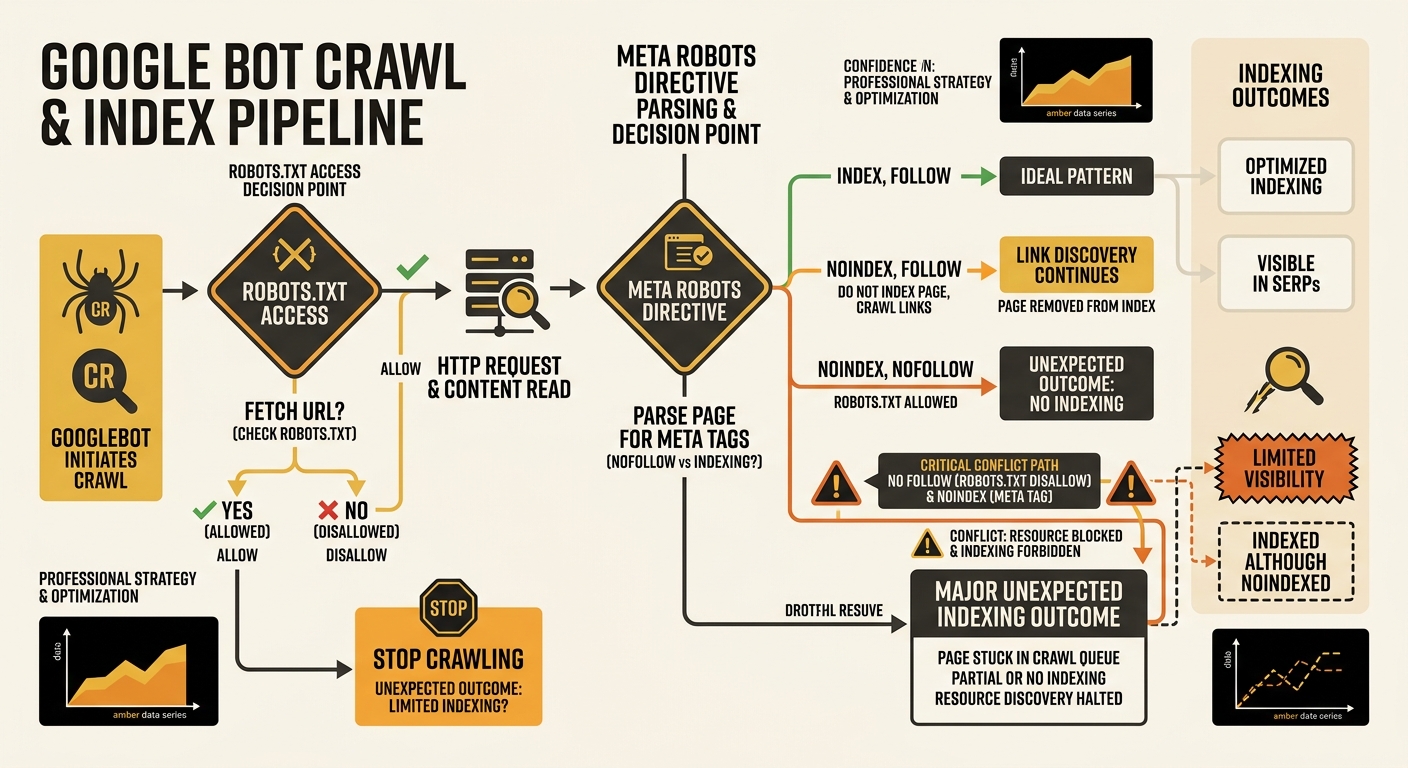
When Meta Robots and Robots.txt Contradict Each Other
Google crawling rules conflicts are one of the quieter ways Australian SMEs sabotage their own visibility. The scenario looks like this: robots.txt blocks Googlebot from a URL, but the page’s meta robots tag says “noindex, follow.” Or the reverse — robots.txt allows crawling, but the meta robots directive blocks indexing on a page the business actually wants ranked.
These two directives operate at different stages of the crawl-index pipeline. Robots.txt controls whether Googlebot can access the page at all. Meta robots controls what Googlebot does after it reads the page. When they conflict, the result depends on which instruction Google encounters first, and the outcome isn’t always predictable.
A common mistake among Australian SMEs using WordPress: a staging site gets moved to production with “Discourage search engines from indexing this site” still ticked. That injects a meta robots “noindex” tag site-wide. The robots.txt file, meanwhile, allows full crawling. Google dutifully crawls every page, reads the noindex directive, and drops the entire site from its index. The HTML is valid. The directives are syntactically correct. And the site is invisible.
Warning: Robots.txt blocking a URL prevents Googlebot from seeing the meta robots tag on that page. If you’re relying on “noindex” to keep a page out of search results but robots.txt blocks the crawl, Google never reads the noindex instruction, and the page can stay indexed indefinitely.
We’ve written a detailed breakdown of how robots.txt and meta robots directives cancel each other out, including the specific WordPress and Shopify configurations that cause the most damage. If your organic traffic dropped without an obvious algorithm change, conflicting crawling rules are worth checking before you blame content quality.
The same principle applies to canonical tag issues. A canonical tag on a blocked page is invisible to Google. These aren’t exotic edge cases — they’re the default configuration on more WordPress and Shopify sites than most agencies would care to admit.
The Open Threads
Google rewrites title tags roughly 33% of the time and meta descriptions even more frequently. The extent to which carefully optimised tags actually appear in search results varies by query, by device, and by whether the page surfaces in a traditional blue link, an AI Overview, or a featured snippet. SMEs can do everything right and still see Google substitute their meta description with a page excerpt it deems more relevant.
The interaction between structured data and AI Overviews is another unresolved area. Google’s AI-generated answers pull from page content, but how much weight structured data carries in selection and citation remains unclear. The robots meta tag now includes directives that control whether content appears in AI Overviews at all, adding a configuration layer that didn’t exist 18 months ago.
And the tooling gap persists. Google Search Console reports structured data errors with a delay that can stretch to days. Screaming Frog validates against Schema.org’s vocabulary, Google’s Rich Results Test validates against Google’s own requirements, and the two don’t always agree. Running both is the current best practice, but even that combination leaves gaps where markup passes every test yet produces no rich result in live search.
The fundamental truth hasn’t changed. Every competitor in your local market has valid title tags. The businesses that rank above you have title tags that are the right length, meta descriptions that match intent, structured data that meets Google’s unpublished requirements, and crawling rules that work together rather than against each other. The distance between “valid” and “effective” is where rankings separate.