
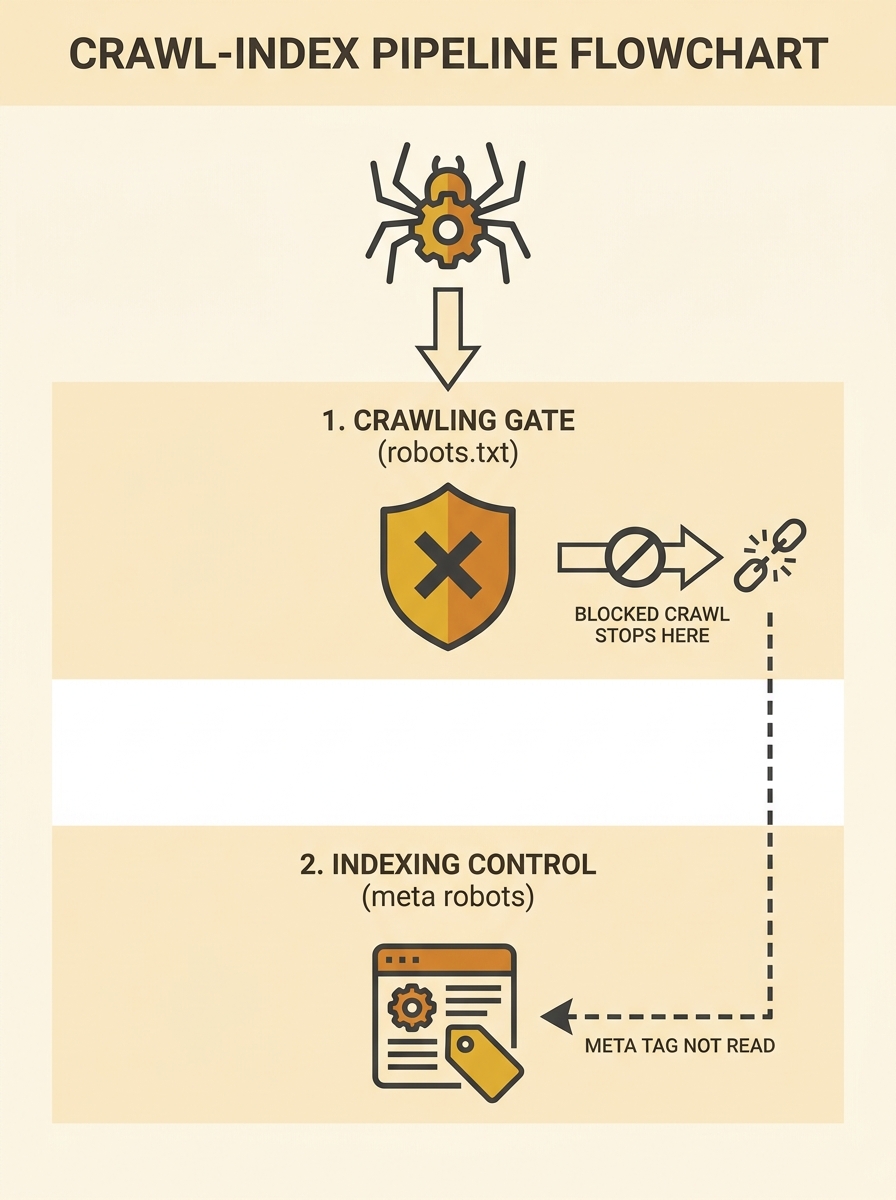
Robots.txt and meta robots tags operate at different stages of Google’s crawl-index pipeline. When they contradict each other, robots.txt wins by default: if it blocks a URL, Googlebot never reaches the page to read its noindex directive. This robots.txt meta robots precedence conflict is the most common Google AI indexing blocker among Australian SMEs.
TL;DR: A crawling and indexing rules conflict happens when robots.txt prevents Googlebot from reaching a page where a meta robots tag sits. Google never reads the tag, so the page enters a dead zone: neither properly indexed nor cleanly excluded. The same conflict blocks AI crawlers (GPTBot, ClaudeBot, OAI-SearchBot) from reading your content for AI Overviews, Perplexity, and ChatGPT citations.
The practical damage goes beyond organic rankings. When Google Ads can’t fully assess your landing page experience because crawling is restricted, your Quality Score drops, your cost-per-click rises, and you spend more on paid search to compensate for organic visibility you’ve accidentally destroyed. Understanding how this two-layer system works is the first step toward fixing it.
The Two-Layer Pipeline: Crawling Happens Before Indexing
Why does robots.txt override meta robots? Because they act at different points in a sequential process. Robots.txt is evaluated at the crawl stage, before Google downloads any page content. Meta robots tags sit inside the HTML of a page, which means Google only reads them after it has already crawled the URL. If robots.txt says “don’t crawl,” the pipeline stops there.
Google’s Search Central documentation on blocking indexing with noindex spells this out directly: “the robots.txt file is blocking the URL from Google web crawlers, so they can’t see the tag.” The consequence is counterintuitive. A page you’ve marked with noindex can still appear in Google’s index (with a blank snippet) if robots.txt blocks crawling of that same URL.
As a Stack Overflow discussion on the topic explains, “You can use robots.txt rules for general things, like disallow whole sections of your site… [Meta tags] can be used to disallow a single page.” The two tools have different scopes and different enforcement points, and the complete SEO reference from Digital Applied adds a critical detail: “Meta robots only works on HTML.” PDFs, images, and non-HTML assets require the X-Robots-Tag HTTP header instead.
This means there are 3 separate mechanisms (robots.txt, meta robots, and X-Robots-Tag) controlling crawl and index behaviour across different file types, and any 2 of them can conflict with each other.
How WordPress Creates This Conflict by Default
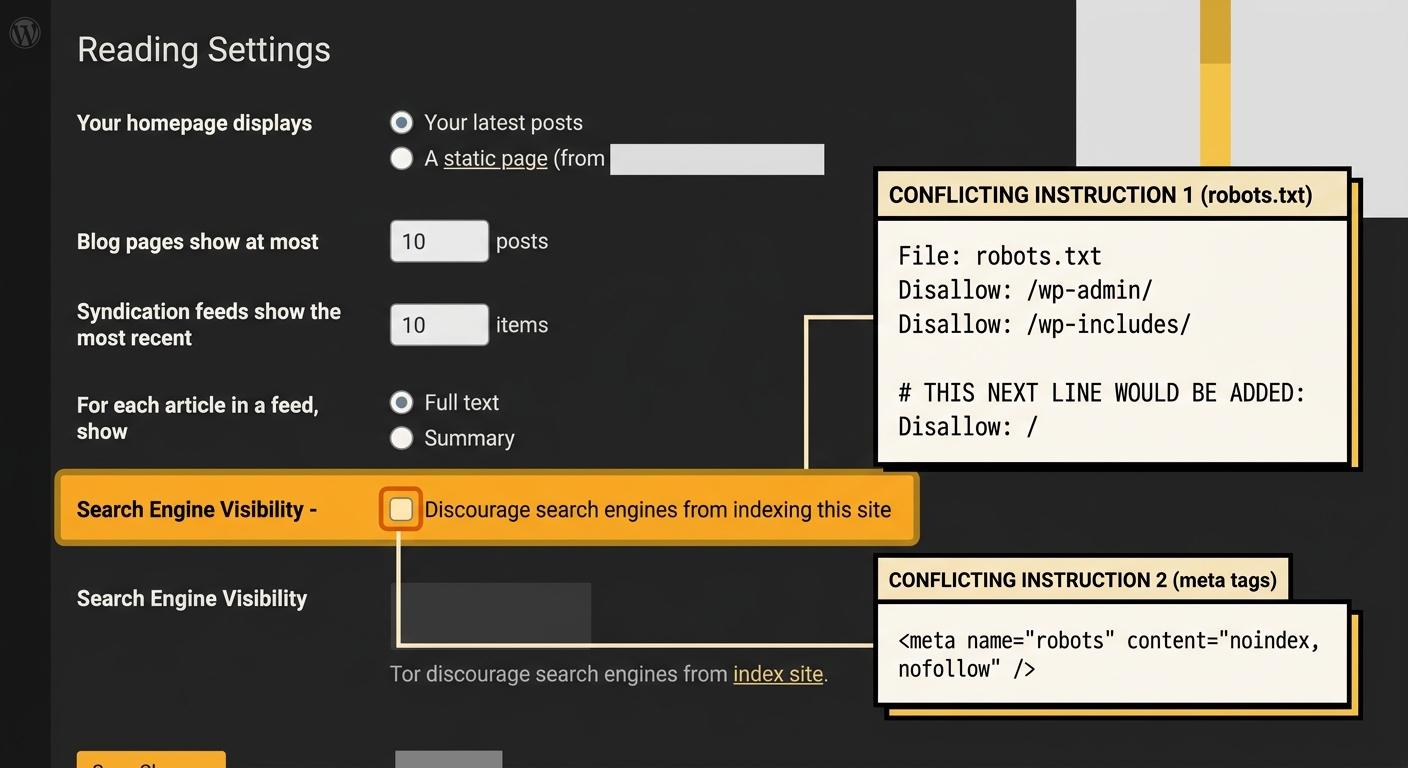
WordPress sites account for roughly 43% of all websites globally, and the platform has a built-in setting that creates precisely this type of technical SEO rule conflict for Australian SMEs who don’t understand what it does.
Under Settings → Reading, there’s a checkbox labelled “Search Engine Visibility” with the instruction “Discourage search engines from indexing this site.” When checked, WordPress does two things simultaneously: it adds a noindex meta tag to every page header, and it modifies the site’s robots.txt file. The WordPress.org support documentation notes that even with these lines in place, “it is totally up to search engines to accept this request or ignore it.”
The problem surfaces during site launches. Developers check this box during staging or development (a sensible precaution), then forget to uncheck it before going live. We’ve written about how this connects to broader site architecture mistakes that block AI indexing, and the pattern is consistent: the default configuration creates a conflict that persists for months before anyone notices traffic isn’t growing.
For paid search, the impact is measurable. Google Ads evaluates landing page experience as 1 of 3 core Quality Score components (alongside expected click-through rate and ad relevance). When Googlebot is discouraged from crawling your landing pages, that assessment becomes incomplete. The result is lower Quality Scores and higher CPCs across your entire account, sometimes by 20-40% per click compared to pages Google can fully evaluate.
AI Crawler Blocking: The Conflict You Didn’t Know Existed
Google’s traditional crawler (Googlebot) is one of at least 8 distinct bot user agents that now attempt to read your content. GPTBot (OpenAI), OAI-SearchBot (OpenAI’s search-specific agent), ClaudeBot (Anthropic), and PerplexityBot each operate independently, and each respects robots.txt rules that specifically target their user agent string.
The Brave AI research confirms the pattern: default robots.txt configurations in many hosting environments and CMS platforms include blanket “Disallow: /” rules that block these AI crawlers while leaving Googlebot untouched. The 2026 DebugBear technical SEO checklist flags this as a critical visibility issue for AI-powered search engines specifically.
Why does this matter for paid search? Because 95% of B2B buyers now anticipate using generative AI for purchase decisions, according to industry research cited across multiple 2026 SEO auditing frameworks. If your competitors appear in ChatGPT and Perplexity responses for your target keywords while your robots.txt blocks those same AI crawlers, you’re funding the gap entirely through ad spend.
When your robots.txt blocks AI crawlers but allows Googlebot, you create a two-tier visibility problem: your pages rank in traditional search but are invisible to every AI answer engine your customers are switching to.
The fix involves auditing your robots.txt for user-agent-specific rules that target GPTBot, ClaudeBot, OAI-SearchBot, and PerplexityBot. We covered the mechanics of this in detail in our piece on how robots.txt and meta robots rules cancel each other out. The short version: you need to explicitly allow each AI user agent you want reading your content, because many default configurations block them.
Mobile-First Rendering Adds a Third Conflict Layer
The NoGood 2026 technical SEO checklist is direct on this point: “If your desktop and mobile experiences differ, the mobile one takes precedence” for both crawling and ranking. Google’s mobile-first indexing has been the default since 2019, but in 2026, the practical consequences for crawling and indexing rules conflict have intensified.
Here’s how the conflict compounds. Your desktop robots.txt might allow Googlebot to crawl /services/. Your mobile rendering might load that same page via JavaScript that Googlebot’s mobile renderer can’t execute. And your meta robots tag on the mobile-rendered version might differ from the desktop version because it’s injected client-side. You now have 3 layers of conflicting instructions: robots.txt (file-level), meta robots (page-level, server-rendered), and a different meta robots state (page-level, client-rendered on mobile).
For Australian SMEs running JavaScript-heavy sites built on React, Angular, or Vue frameworks, this creates a specific paid search problem. Google Ads’ landing page crawler uses a rendering process similar to Googlebot’s mobile renderer. When that renderer can’t execute your JavaScript properly, it evaluates a blank or partially loaded page. Landing page experience scores drop, Quality Scores decline, and your cost per conversion increases even though the page works perfectly for human users on their phones.
ROI.com.au’s guidance for Australian businesses recommends implementing schema markup relevant to local business details (address, opening hours, services, products) as part of the fix. Schema is processed before full rendering, so it gives Google structured data even when JavaScript rendering fails. We’ve covered which schema types actually matter for Australian SMEs separately.
Warning: Test every robots.txt rule against real URLs in Search Console’s robots.txt Tester before deploying changes. A single misplaced wildcard can block thousands of pages, and the tester is the only way to verify which URLs are affected before Google’s next crawl.
The Paid Search Cost of Getting This Wrong
The connection between technical SEO rule conflicts and paid search costs is arithmetic, not theoretical. When organic visibility drops to zero for a given keyword set (because crawling rules block indexing), 100% of your traffic for those terms must come through paid channels. If those same crawling conflicts degrade your landing page Quality Score from 7 to 4, your average CPC can double.
For a typical Australian SME spending $3,000-$8,000 per month on Google Ads, resolving crawling and indexing conflicts often produces a 15-25% reduction in effective CPC within 60 days, simply because landing page experience scores improve once Google can properly crawl and render the pages.
This is also where AI visibility creates a compounding effect. The SEO for Small Business Australia guidance from Google I/O 2026 recommended that businesses “audit service pages for AI-citation worthiness” with clear claims, specific data, expert authorship, and dated content. Pages that AI crawlers can read and cite become free traffic sources that reduce paid search dependency over 6-12 months. Pages blocked by robots.txt conflicts never enter that equation.
If you’re noticing pages shifting to “not indexed” status without explanation, our piece on why Google moves pages to that status covers the diagnostic process.
Where The Model Breaks
This two-layer precedence model (robots.txt first, meta robots second) is clean in theory but fragile in practice, for three reasons.
First, the model assumes you control one robots.txt file. Many Australian SMEs run subdomains (shop.example.com.au, blog.example.com.au) that each need their own robots.txt, and configurations across subdomains almost never stay in sync. A conflict on your blog subdomain might block 40-60% of your indexable content without affecting your main domain at all.
Second, CDN and hosting-level caching can serve stale robots.txt files for 24-72 hours after you’ve updated them. You might fix a conflict in your CMS, verify it in the file editor, and still have Google reading the old version from a cached CDN node for days.
Third, the 8+ AI crawler user agents don’t all behave identically. GPTBot and ClaudeBot respect robots.txt. Some newer or less-documented AI scrapers don’t. Building your crawl access rules around a model that assumes universal compliance will always have gaps, and those gaps shift as new AI agents appear quarterly.
The mechanism works. It’s well-documented and predictable. But it requires ongoing monitoring rather than a one-time fix, because every CMS update, plugin change, or hosting migration can reintroduce the exact conflicts you’ve already resolved. Treating crawl access as a set-and-forget configuration is how most Australian SMEs end up back in the same dead zone within 12 months.