Splitting link equity across URL variants (trailing slashes, UTM parameters, HTTP vs HTTPS) can reduce a page’s effective keyword competitiveness by up to 40%, according to 2026 indexing analysis. For Australian SMEs already fighting for thin margins on page one, that single HTML element most site owners never inspect is the difference between visibility and obscurity.
TL;DR: Canonical tags fail silently through CMS misconfiguration, robots.txt conflicts, and content similarity gaps below Google’s 85% threshold. Australian SMEs lose up to 40% of ranking power when canonical signals break across URL parameters, cross-domain syndication, and mobile/desktop mismatches. Quarterly audits using Search Console’s URL Inspection tool are the minimum viable defence.
The Silent Authority Drain Across URL Variants
Canonical tags fail so often for small sites because the tag is a suggestion, not a directive. Google treats rel=canonical as one signal among many, and when other signals contradict it, the tag gets ignored without warning.
Sites with a high ratio of non-canonical duplicates, over 15% of total URLs, experience a 22% delay in indexing new content, according to Search Engine Land’s 2026 canonicalization guide. Search engines waste crawl budget de-conflicting identical content blocks instead of discovering new pages. For a 200-page e-commerce site with 30+ duplicate variants floating around, that’s real revenue sitting in a queue.
Google’s own Search Central Blog warns against one of the most common mistakes: “Avoid adding a rel=canonical from a category or landing page to a featured article,” noting that the canonical designation also implies the preferred display URL. Australian retailers regularly break this rule by canonicalising filtered category pages to their parent categories, which collapses dozens of indexable pages into one.
The core problem is that canonical tag implementation in Australia tends to be set-and-forget. A developer adds the tag during the initial build, nobody audits it after CMS updates or plugin changes, and the tag slowly drifts out of alignment with everything else on the site.

URL Parameter Canonicalization Breaks More Sites Than Any Other Issue
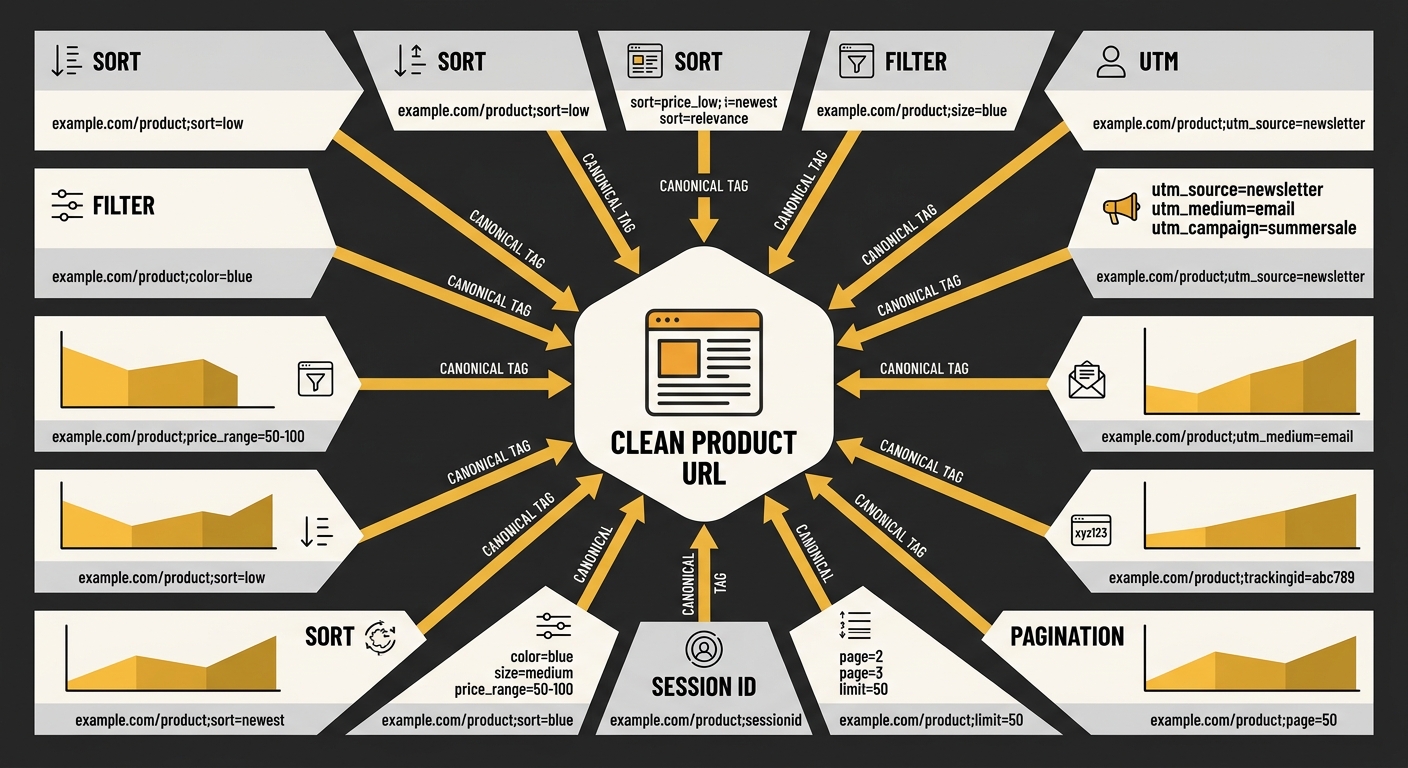
Every time a CMS appends a session ID, tracking parameter, sort order, or filter selection to a URL, it creates a new indexable page with identical content. A single product page can spawn 15 to 20 parameter variants: sort=price, colour=blue, utm_source=facebook, page=1. Each one dilutes the original page’s authority unless canonical tags consolidate them back to the clean URL.
Search Engine Journal’s guide to URL parameter handling confirms that rel=canonical “reduces duplicate content issues” and “consolidates ranking signals to fewer pages” across all parameter types, but notes the implementation requires moderate technical effort. That moderate effort description understates the reality for most Australian SMEs running WordPress with WooCommerce or Shopify with custom apps, where plugins generate parameters the site owner doesn’t know exist.
The interaction between robots.txt and canonical tags creates an especially dangerous blind spot. A TechSEO practitioner on Reddit identified the mechanism: “Robots.txt stops Google from seeing the canonical tags. If all links have parameters, you effectively have no internal links.” If your robots.txt blocks parameterised URLs, Google never reaches the page, never reads the canonical tag, and your duplicate content consolidation strategy collapses entirely. We covered how robots.txt and meta robots rules cancel each other out in detail, and the same principle applies to canonical signals.
The fix sequence matters. First, ensure parameterised URLs aren’t blocked by robots.txt. Second, add canonical tags pointing to the clean URL. Third, configure your CMS templates to generate correct canonicals automatically so new parameters don’t reintroduce the problem. Patching each URL individually is a losing game when your marketing team adds new UTM parameters every week.
Self-Referential Canonical Tags Prevent Future Contamination
Self-referential canonical tags, where a page’s canonical tag points to its own URL, sound redundant. They aren’t. Every unique page should declare itself as canonical to protect against parameter contamination that hasn’t happened yet.
Without a self-referential tag, a new tracking parameter appended by a marketing tool creates a variant with no canonical signal at all. Google then picks between two identical pages with no guidance, and the wrong one can win. Best practices documented in the SEO-Wiki canonical guide recommend ensuring self-referential canonical tags are identical on mobile and desktop versions and conducting monthly audits using tools like Screaming Frog or Ahrefs for automatic canonical checks.
This is where Australian SMEs with separate mobile subdomains (m.example.com.au) get caught. If the desktop page has a self-referential canonical but the mobile version either lacks one or points to a different URL, you’ve created a split signal. Google’s mobile-first indexing means the mobile version’s canonical tag is the one that counts. If it’s wrong, your desktop page’s careful configuration is irrelevant.
The HTTP vs HTTPS mismatch is another quiet killer. If you’ve completed your HTTPS migration but your canonical tags still reference HTTP URLs, every page on your site sends Google a contradictory signal. Google usually resolves this correctly, but “usually” is doing heavy lifting for a fix that takes ten minutes in your CMS template.
Cross-Domain Canonical SEO and the Syndication Trap
Cross-domain canonical SEO matters the moment your content appears on another website. Publishers and Australian businesses that syndicate content to industry directories, partner sites, or aggregators without cross-domain canonical tags lose an average of 40% of potential organic traffic to those third-party sites within the first week.
The mechanism is straightforward: larger aggregator sites get crawled more frequently, index the content faster, and Google assigns them as the canonical source. Your original page, published first, written by you, becomes the duplicate in Google’s eyes. A cross-domain canonical tag on the partner’s version pointing back to your original URL tells Google where the content originated and consolidates link signals to your domain.
Google’s algorithm requires an 85%+ match in main content for canonical tags to be respected. Drop below that threshold and Google ignores the tag entirely, indexing both versions independently.
Google’s webmasters suggest choosing your preferred domain first, then handling duplication within your site before tackling cross-site duplicate content, as outlined in Power Digital Marketing’s cross-domain analysis. The sequence matters because internal canonical confusion amplifies cross-domain problems. If Google can’t determine the canonical version on your own site, a cross-domain canonical tag pointing back to one of several competing internal URLs creates a chain that resolves to nothing useful.
Search Engine Land’s 2026 guide notes that canonicalization “plays an equally important role in GEO” (generative engine optimisation) because both traditional search engines and generative engines consolidate sources when interpreting content. But LLMs don’t follow canonical tags the way Googlebot does. Aggressive consolidation through proper canonical implementation and, where needed, robots.txt blocking of duplicate variants, becomes more important as AI-driven search visibility grows alongside traditional rankings.
The Canonical Signal Chain: A Three-Layer Audit Framework
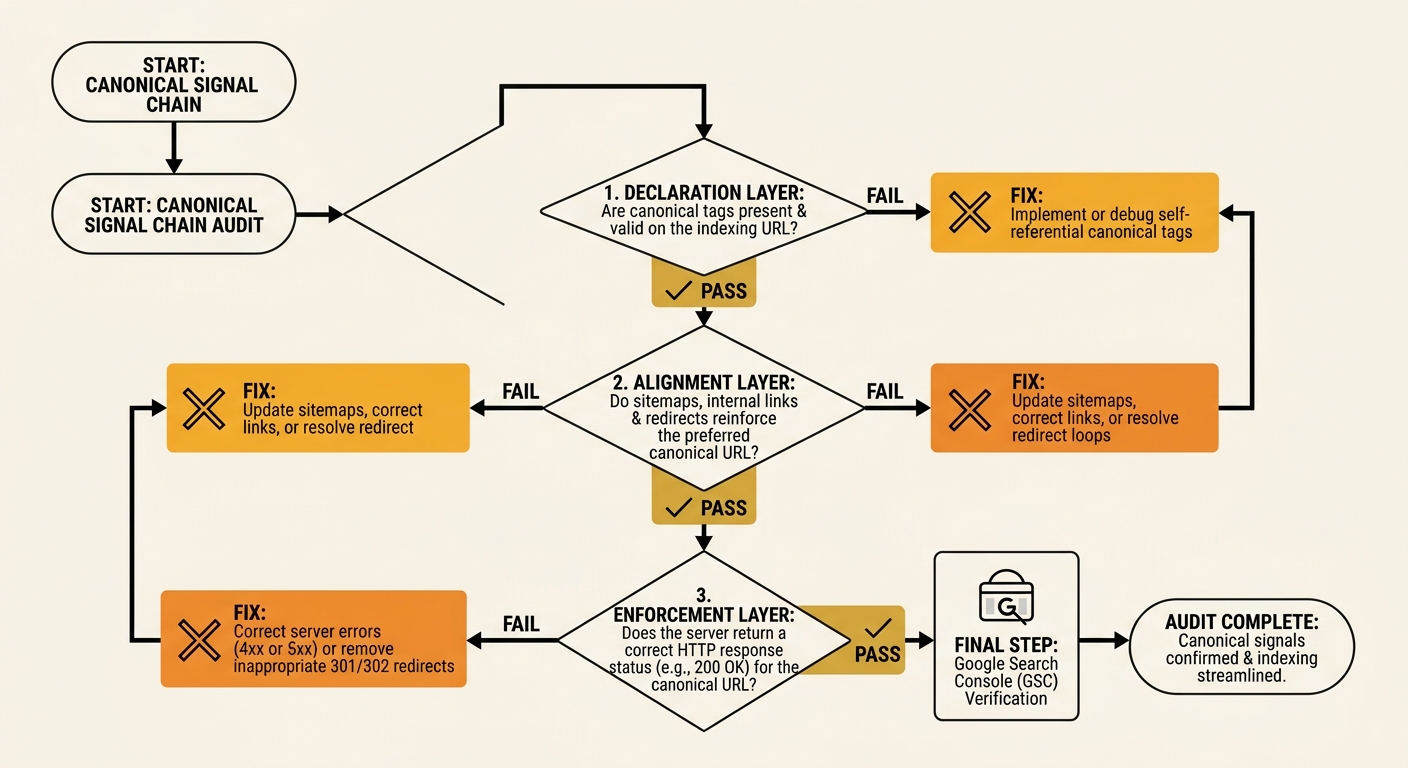
Treating canonical issues as isolated tag-level bugs misses the systemic pattern. Canonical failures cascade through three layers, and fixing one without checking the others wastes time. We call this the Canonical Signal Chain:
Layer 1: Declaration. Does the canonical tag exist and point to the correct URL? Check for missing tags, tags pointing to 404 pages, tags referencing HTTP when the site runs HTTPS, and tags dynamically generated by CMS plugins that output incorrect URLs. Moz’s canonicalization guide warns that e-commerce and CMS-driven sites frequently generate incorrect canonical versions dynamically, and periodic checks are the only defence.
Layer 2: Alignment. Do your XML sitemap, internal links, and redirect rules agree with your canonical tags? If your sitemap includes URLs that your canonical tags say aren’t canonical, you’re sending contradictory signals. If internal links point to parameter-heavy URLs while your canonicals point to clean URLs, the link equity flows to the wrong version first. Run this check as part of your broader SEO debugging workflow since canonical alignment rarely fails in isolation.
Layer 3: Enforcement. Does Google actually accept your canonical declaration? Google requires that 85% content similarity threshold for canonical tags to be respected. If the pages differ significantly through different headers, product descriptions, or supplementary content blocks, Google will ignore the tag and index both versions. Use the URL Inspection tool in Google Search Console to verify which URL Google has selected as canonical. The answer will frequently differ from what your HTML declares.
Warning: Canonical chains, where Page A canonicalises to Page B, which canonicalises to Page C, are a common CMS artefact after site migrations. Google follows one hop but often drops chains of two or more. Audit for chains quarterly, especially after CMS updates.
| Canonical Issue | Detection Method | Typical Impact | Fix Complexity |
|---|---|---|---|
| Missing self-referential tags | Screaming Frog crawl | Parameter variants indexed as separate pages | Low |
| HTTP/HTTPS mismatch in tags | Site audit tool + manual check | Split authority across protocols | Low |
| Robots.txt blocking parameterised URLs | Google Search Console + robots.txt tester | Canonical tags never read by Google | Medium |
| Cross-domain canonical absent | Manual review of partner pages | 40% traffic loss to aggregator within 1 week | Medium |
| CMS dynamic canonical errors | Periodic Screaming Frog or Ahrefs crawl | Each variant gets its own incorrect canonical | Medium |
| Canonical chains (A→B→C) | Screaming Frog redirect chain report | Google drops the chain, indexes wrong page | Medium |
| Content similarity below 85% | Manual comparison or Copyscape | Google ignores canonical tag entirely | High |
For Australian e-commerce sites recovering from traffic losses, the kind where rebuilding content depth restored 60% of lost traffic, canonical cleanup is often the unglamorous precondition that makes content improvements stick. Without clean canonical signals, new content competes against its own duplicates.
What The Numbers Still Can’t Answer
The 40% authority dilution figure, the 22% indexing delay, the 85% similarity threshold: these numbers describe symptoms well. They don’t explain why the same CMS platforms keep generating the same canonical errors after a decade of documentation. WordPress with WooCommerce, Shopify with custom apps, Magento with third-party extensions: each has its own canonical failure modes, and the vendor-specific data on how often these platforms ship broken defaults remains thin.
The AI search dimension adds another gap in the data. LLMs don’t respect canonical tags the way Googlebot does. How much citation dilution occurs when duplicate content appears across AI training data without canonical consolidation is unmeasured territory, and the 40% syndication loss figure from traditional search gives us a rough lower bound, not a precise answer for generative engines.
What the data does confirm is that canonical tag implementation for Australian businesses sits in a gap between “too technical for the business owner” and “too routine for the developer to revisit.” The tags get set once, break silently through CMS updates and new marketing tools, and stay broken until a traffic drop forces an audit. Quarterly canonical checks using Google Search Console’s URL Inspection tool paired with a crawling tool like Screaming Frog are the minimum viable monitoring cadence. Anything less and you’re finding problems after they’ve already cost you rankings you’ll spend months trying to recover.