
Screaming Frog took over nine hours to finish crawling Springfield Clinic’s domain. The multi-location healthcare provider in the US Midwest had accumulated roughly 60,000 indexed URLs, most of which shouldn’t have existed. Their appointment scheduling system generated a new URL for every date picker selection. Their provider directory created parameterised variations for each filter combination. Their event calendar had spawned thousands of pages for past dates stretching back years. To a patient booking an appointment, the site looked fine. To Googlebot, it was a maze with no discernible centre.
Springfield’s cleanup reduced their total indexed page count by 60% and produced a 30% increase in daily search volume within months. The specifics of how they diagnosed, cut, and recovered make this one of the more instructive site architecture audit case studies in recent years.
Nine Hours Inside a Crawler
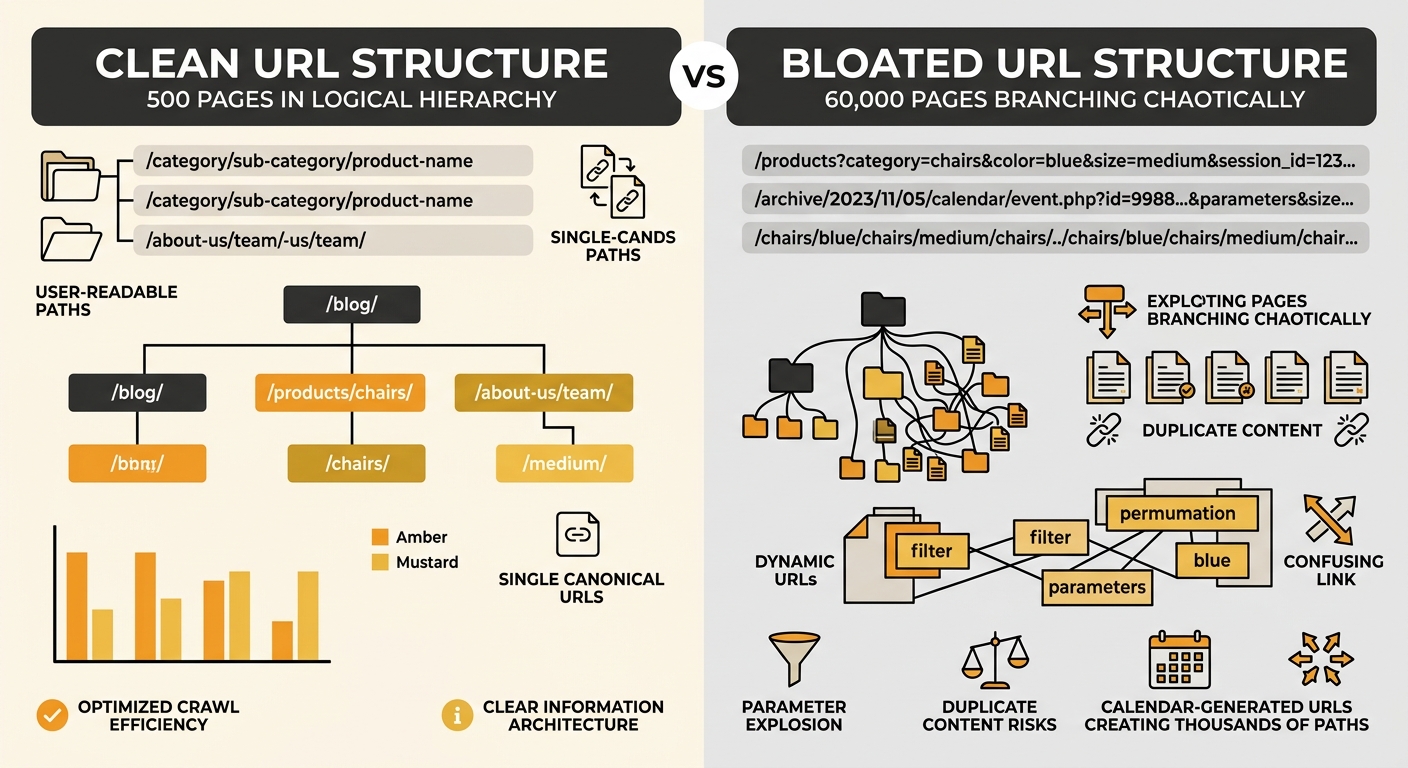
The first sign of trouble wasn’t a ranking drop. It was crawl time. When Springfield’s SEO team ran a full-site crawl, the sheer duration flagged something structural. A domain with legitimate content across, say, 500 service pages and 200 provider profiles shouldn’t need 60,000 URLs to represent itself.
The crawl report revealed familiar culprits. Dynamic calendar pages accounted for thousands of URLs, each representing a single date view that offered zero unique content. Filter combinations on the provider directory (speciality + location + insurance accepted) multiplied into tens of thousands of near-identical pages. And session IDs appended to URLs created duplicate versions of pages that already existed in clean form.
Google’s own URL structure documentation is direct about this: avoid long ID numbers, excessive parameters, session IDs, and dynamic calendars. These generate indexing problems because crawlers treat each parameterised URL as a potentially unique page. When your crawl budget gets spent on 55,000 pages that add no value, the 5,000 pages that actually matter get crawled less frequently and indexed less reliably.

Springfield’s crawl budget was being consumed by phantom pages. Their real content, the service descriptions and provider profiles that patients actually searched for, competed for attention with an ocean of generated noise.
How 60,000 URLs Get Created Without Anyone Noticing
The answer is almost always incremental. Nobody at Springfield decided to build 60,000 pages. The appointment booking system was installed and created crawlable URL patterns for each date. Nobody blocked those from indexing. The provider directory added filter functionality, and each filter state generated its own URL. Nobody set canonical tags. The event system archived past events on their own URLs rather than consolidating them into a single archive page. Nobody noticed because each system worked fine in isolation.
This is how URL debt accumulates. It mirrors the broader pattern of technical SEO debt that affects organisations of every size. Each individual feature launch seems harmless. But without someone reviewing the crawlable URL patterns each system creates, the domain bloats quietly over months and years.
For Australian businesses running WordPress with a few plugins, or Shopify stores adding product filters, the mechanism is identical. A faceted navigation system that lets customers filter by colour, size, material, and price range can generate hundreds of indexable URLs from a single product category. If those filter combinations produce crawlable URLs without canonical tags or appropriate robots.txt directives, you’re building your own version of Springfield’s problem.
Warning: Hash-based routing (URLs with # fragments) creates the opposite problem. Google won’t crawl content behind hash routes at all, which means pages that should rank individually become invisible to search engines entirely. If your single-page application uses fragment-based navigation, each content view that deserves its own ranking needs a proper server-rendered URL.
Cutting 60% of Pages Without Losing Anything Valuable
Springfield’s team faced the decision every site architecture audit eventually arrives at: what to consolidate, what to block, and what to delete. Their approach followed three steps.
First, they identified which of the 60,000 URLs received any organic traffic at all. The answer was roughly 3,000 pages. The remaining 57,000 URLs had never brought in a single visitor from search. These were the calendar date pages, the obscure filter combinations, and the session-ID duplicates.
Second, they categorised those 57,000 pages by type. Calendar pages were blocked from indexing entirely via robots.txt. Filter combination pages were consolidated using canonical tags pointing back to the parent category. Session ID parameters were stripped from URLs at the server level. Past event pages older than two years were merged into annual archive pages.
Third, they redirected any URLs that had accumulated backlinks (a small number of calendar pages had been linked from local news sites covering specific events). Losing those inbound links would have meant losing link authority flow to the domain entirely.
When your crawl budget gets spent on 55,000 pages that add no value, the 5,000 pages that actually matter get crawled less frequently and indexed less reliably.
The result was a domain with approximately 24,000 indexed URLs. Still a large site, but one where the vast majority of indexed pages had a clear purpose, unique content, and a logical place in the site’s hierarchy.
As Search Engine Land’s guide to site architecture puts it, strong structure makes it easy for visitors to find what they need and for search engines to crawl and understand content. When navigation is intuitive, users stay longer, convert more, and are less likely to bounce. Springfield’s cleaned-up structure reflected this directly in their engagement metrics.
Reconnecting Link Authority to the Pages That Mattered
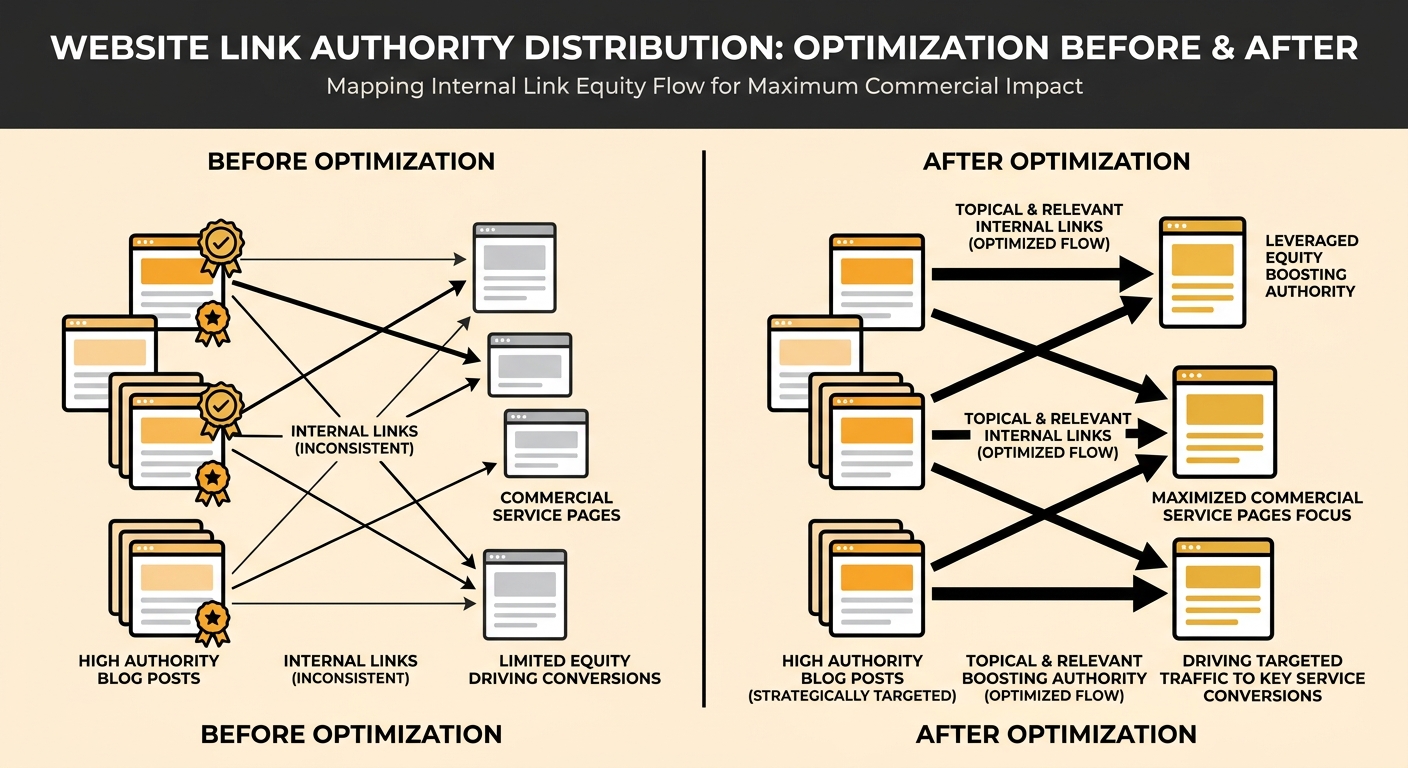
URL consolidation solved the crawl budget problem, but it exposed a second issue: link authority flow across the remaining pages was poorly distributed.
Springfield’s most linked-to pages were their homepage and a handful of blog posts about common health topics. Their service pages, the ones that actually drove patient bookings (orthopaedics, cardiology, primary care), had weak internal linking. A patient landing on a blog post about knee pain had no clear path to the orthopaedic services page. The authority those blog posts carried wasn’t flowing to the pages that generated revenue.
This is a pattern Moz’s internal linking research addresses directly: by directing internal links from high-authority pages to less authoritative but commercially important pages, you distribute link equity where it creates business value. Springfield’s team audited their top 50 pages by referring domain count and added contextual internal links from each one to the relevant service page.
The effect compounded. Service pages climbed in rankings because they now received authority from pages that Google already trusted. And the internal linking created clearer user pathways, reducing the “broken journeys” phenomenon where visitors reach dead-ends with no obvious next step. GA4 path analysis showed that patients who landed on blog content were now 2.4 times more likely to visit a service page before leaving the site.
For Australian businesses, the internal linking principle applies regardless of scale. If your site has a blog driving organic traffic but your service pages sit disconnected from that content, you’re accumulating authority in pages that don’t convert and starving the ones that do. We’ve written about how content clustering addresses this structural gap, and Springfield’s case shows the measurable impact of fixing it.
The Recovery Curve After Springfield’s Cleanup
The 30% increase in daily search volume didn’t arrive overnight. Springfield’s recovery followed a pattern familiar to anyone who’s managed a large-scale site migration: an initial dip as Google recrawled and reindexed the restructured domain, followed by a steady climb over approximately eight weeks as the cleaner architecture took effect.
Three specific metrics told the story. Crawl frequency on their service pages increased measurably within the first two weeks, because Googlebot was no longer spending its budget on thousands of calendar and filter pages. Average position for their target keywords (service + location combinations like “cardiology Springfield IL”) improved by an average of 4.2 positions over three months. And organic click-through rate on their service pages rose, likely because Google was now serving the correct, canonical version of each page rather than a parameterised duplicate with an ugly URL.
The cost of waiting was real. Springfield estimated they’d been operating with bloated URL structure for over three years before the audit. That’s three years of diluted crawl budget, three years of link authority leaking into dead-end pages, and three years of patients seeing confusing URLs in search results that may have reduced click confidence.
For any business running a site architecture audit today, Springfield’s case reinforces something specific: the URL structure you can see in your browser bar is the surface layer. The crawlable URL patterns underneath, the ones generated by your CMS, your booking system, your product filters, and your archive logic, are where the real damage accumulates. Fix the visible pages all you like. If you haven’t audited what your systems are generating behind the scenes, you’re probably running a version of Springfield’s problem at a smaller scale.