
On Reddit’s r/TechSEO, an auditor tested AI crawlers against a few hundred websites across different industries to answer a straightforward question: can GPTBot, ClaudeBot, and PerplexityBot actually read your website’s metadata? The results, shared with the community, were blunt. Nine out of eleven metadata types scored zero. Schema markup, structured data carefully maintained by technical SEO teams, functionally invisible to the AI systems now powering a growing share of search results.
That test didn’t make headlines, but it should have. Because this week, Search Engine Journal published a column calling for a new audit layer specifically for AI crawlers, and Cloudflare’s Q1 2026 radar data confirmed that 30.6% of all web traffic now comes from bots, with AI crawlers representing a significant and growing portion. The gap between what your audit tools check and what AI systems actually see on your site is widening fast.
For paid search teams, this matters more than it might first appear. AI-generated summaries now show up in close to 87% of Google searches, pushing both organic and paid results further down the page. If your landing pages are invisible to the AI layer that generates those summaries, your cost per acquisition rises and your ad real estate shrinks. Your standard technical SEO framework for 2026 won’t flag the problem.
The r/TechSEO Metadata Test and Its Zero Scores
The Reddit test was simple in design. The auditor crawled sites the way AI bots do: without rendering JavaScript, without processing schema markup the way Googlebot does. The crawlers pulled raw HTML, evaluated what was accessible in that raw state, and scored metadata visibility across eleven types.
Nine came back zero.
The structured data that site owners had painstakingly implemented in JSON-LD wasn’t being parsed. Open Graph tags, Twitter Cards, FAQ schema, Product schema — all invisible to text-first AI crawlers that don’t execute client-side code.
The auditor’s observation was direct: schema markup is “basically invisible to AI systems. They’re text-first, so all that structured data you’re carefully maintaining might as well not exist.”
This finding aligns with what we’ve covered when examining how standard audit tools create a false sense of completeness. Your Screaming Frog crawl shows green ticks for schema implementation. Your audit scorecard says 95%. But the AI crawlers that increasingly determine whether your content gets cited in an AI Overview or ChatGPT answer can’t see any of it.

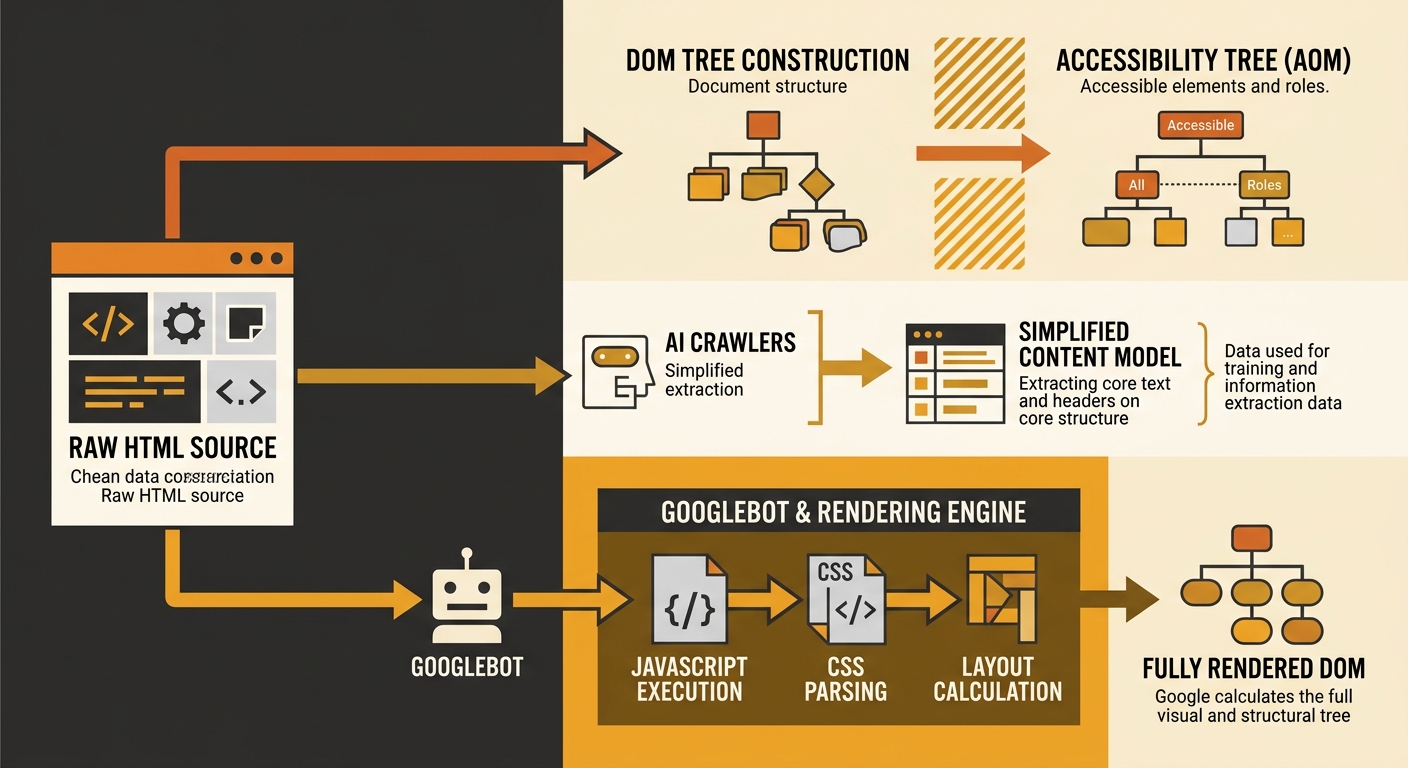
AI Crawlers, the Accessibility Tree, and Why JavaScript Is the Wall
To understand why the zero scores happen, you need to understand how AI crawlers actually parse a page. They don’t render it the way Chrome does. They don’t build a full DOM, execute JavaScript, and paint pixels. Most AI crawlers work from the raw HTML response your server sends.
This is where accessibility tree parsing becomes relevant. As Mozilla’s developer documentation explains, the DOM tree contains objects representing all the markup’s elements, attributes, and text nodes. Browsers then build an accessibility tree from the DOM, which assistive technologies like screen readers use to interpret page content.
AI crawlers behave more like screen readers than like visual browsers. They parse the content they can access in the raw HTML, and they build something functionally similar to an accessibility tree to extract meaning, structure, and relationships. If your key content loads via a React component after initial page render, or your product details populate through a JavaScript API call, those crawlers see an empty shell.
Understanding this mechanism tells you exactly where to look for audit blind spots: anywhere your site relies on client-side rendering to deliver meaningful content. And for paid search teams running JavaScript-heavy landing pages built for conversion tracking and dynamic personalisation, the overlap is significant. The pages you’ve optimised hardest for paid conversions may be the same pages AI crawlers can’t read at all.
Where Paid Search Budgets Leak Into the Audit Gap
Here’s the connection paid search managers need to pay attention to. When AI-generated summaries dominate close to 87% of Google searches, as recent research has shown, the SERP your ads compete on changes shape. AI Overviews occupy prime real estate above organic results. Paid ads get pushed down or compressed. Click-through rates for ads on queries with AI Overviews are measurably lower than on queries without them.
If your site’s content can’t be read by AI crawlers, it won’t appear in those AI Overviews. That means you’re paying for ad placement on a SERP where a competitor’s content is being surfaced for free in the AI summary, while your paid result sits further down the page. Your CPA goes up. Your impression share might hold, but your conversion rate drops because the AI answer has already addressed the user’s intent before they scroll to your ad.
Cloudflare’s Q1 2026 data gives this a quantitative edge. GPTBot crawls roughly 1,300 pages per referral it sends back to a site. ClaudeBot crawls 20,600 pages per referral. Meta’s crawler returns zero referrals. The crawl-to-referral ratio tells you which bots are worth accommodating and which are consuming server resources for nothing.
The gap between your traditional SEO dashboard and your actual AI presence creates a strategic blind spot that competitors can exploit.
For paid search planning, this data should inform budget allocation. If AI Overviews are cannibalising top-of-funnel queries you’re currently bidding on, and your content isn’t visible to the crawlers generating those overviews, you’re fighting an increasingly expensive battle on two fronts. The AEO maturity model we’ve previously covered provides a four-stage framework for assessing where your organisation sits on AI search readiness, and stages one and two are precisely where most Australian businesses remain stuck.
Search Engine Journal’s Five-Layer Proposal
The column published this week lays out a specific AI crawler SEO audit framework that adds five new layers to the standard checklist. It’s worth walking through each one because the framework maps directly onto the failures the Reddit test exposed.
Layer one: AI crawler access. Your robots.txt needs explicit rules for GPTBot, ClaudeBot, PerplexityBot, Google-Extended, and CCBot. Note that Google-Agent, announced in March 2026, ignores robots.txt entirely and requires server-side authentication to block. If your crawling rules already conflict, you may be unintentionally blocking the crawlers you want while failing to block the ones consuming bandwidth for zero return.
Layer two: JavaScript rendering. Use a simple curl command or “View Source” on your pages. If critical content doesn’t appear in the raw HTML, AI crawlers can’t see it. The recommendation is to migrate single-page applications to server-side rendering or static site generation.
Layer three: Structured data for AI. JSON-LD is now present on 53% of the top ten million sites, but the Reddit test showed AI crawlers still can’t parse it. The column suggests treating structured data as a Googlebot-specific asset and ensuring the same information appears in plain HTML text for AI crawlers.
Layer four: Voice engine optimisation. Concise, natural-language answers formatted in a way that spoken query systems can pick up. Schema types like Question and Answer become more relevant here.
Layer five: Agentic SEO and automation. Tools like PromptWatch now track AI visibility and crawler behaviour separately from traditional Googlebot metrics, and marketing teams are starting to run both stacks in parallel. Most teams using these tools report they complement rather than replace existing platforms like Screaming Frog or Sitebulb.
The column makes an important distinction: robots.txt rules for AI crawlers don’t affect Google rankings. Accessibility tree optimisation doesn’t move keyword positions. Content position scoring has nothing to do with search indexing. This is an adjacent discipline growing out of technical SEO skills, not a replacement for existing work. But for AI search optimisation, it’s now essential.

What Those Zero Scores Actually Cost
The r/TechSEO test didn’t track commercial outcomes. But the maths isn’t hard to do. If nine out of eleven metadata types are invisible to AI crawlers, and AI-generated answers are appearing on nearly nine in ten Google searches, then the structured data investment most sites have made over the past five years has a growing blind spot that compounds every quarter.
For Australian businesses running paid search campaigns alongside organic strategies, the audit gap creates a compounding problem. You can’t offset declining organic visibility with higher ad spend if the underlying reason for that decline goes undiagnosed because AI crawlers can’t read your content. And your existing tools won’t diagnose it, because they weren’t built to check for it. As we’ve explored when looking at technical SEO debt in Australian businesses, the cost of ignoring infrastructure problems grows quietly until it becomes the single biggest line item on your recovery plan.
Warning: If your paid search landing pages rely on client-side JavaScript rendering, AI crawlers see an empty page. This means your content won’t appear in AI Overviews for the same queries you’re bidding on, increasing your reliance on ad spend for visibility you could be earning.
The practical move is to run a second audit pass, separate from your Screaming Frog or Sitebulb report, that evaluates your site from the perspective of a text-only, non-rendering crawler. Check what GPTBot actually sees when it hits your pages. Compare your server logs for AI bot user-agents against your Googlebot logs. Start treating this gap with the same urgency you’d give a broken conversion tracking pixel, because the commercial impact is comparable and the measurement tools are only now catching up to the problem.