
Screaming Frog, Ahrefs, and Semrush confirm your site is crawlable, renders properly, and loads fast. They cannot tell you whether Google or ChatGPT considers your business trustworthy enough to cite. That gap between machine-readable and machine-trusted is where most Australian SMEs lose visibility they never knew they had.
The Audit Template That Held for Fifteen Years
Technical SEO audits crystallised into a standard checklist sometime around 2010–2011. The steps were consistent across every agency and freelancer: check HTTPS, fix crawl errors, compress images, set canonical tags, submit sitemaps, verify robots.txt directives. Google’s algorithm carried over 200 ranking factors according to SpyFu’s audit framework, but the technical audit focused on maybe 30 of them, all related to accessibility and speed.
This made sense. If Google’s crawler couldn’t reach your pages, nothing else mattered. The entire audit was structured around one question: can the machine read this? Load time, mobile responsiveness, redirect chains, broken links, duplicate content. Every item on the checklist answered some version of that single question.
And for a long time, answering it was enough. Sites that were crawlable, fast, and error-free consistently outranked sites that weren’t. The audit template worked because the search engines it served were essentially pattern-matching machines that rewarded mechanical correctness.

Schema Markup Enters the Picture
Structured data existed for years before it started mattering to audits. JSON-LD gained slow traction through 2018–2022, treated as a nice-to-have rather than a requirement. The shift happened when Google began generating rich results from schema at scale, and when AI systems started using structured data as a primary extraction layer.
By early 2026, approximately 53% of the top 10 million websites use JSON-LD, according to industry crawl data. That number reflects a tipping point: structured data moved from bonus feature to baseline expectation. As the Page One Power team wrote in their 2026 schema-edition audit checklist, “the machines reading your content can understand what it is, who made it, and whether it can be cited with confidence” — and schema markup is what bridges the gap between a technically clean site and a legible one.
This distinction between “clean” and “legible” matters. A clean site has no crawl errors, fast load times, and appropriate markup. A legible site goes further: the machines parsing it can identify authorship, extract claims with confidence, and verify the entity behind the content. We covered the priority order for schema types in a separate piece, but the key point here is that schema moved machine-readable SEO from “can Google see this page?” to “can Google understand what this page is about, and who stands behind it?”
AI Search Blows the Door Open
The arrival of ChatGPT search, Perplexity, and Google’s AI Overviews as mainstream answer surfaces changed what “machine-readable” actually required. These systems don’t just crawl and index. They read, evaluate, attribute, and decide whether your content is worth citing in a synthesised answer.
Google’s Search Advocate John Mueller has publicly advised against serving raw markdown or flattened content to AI agents, recommending well-written semantic HTML as the correct machine-readable format. Flattening content removes hierarchy and context — the exact signals AI systems need to cite with confidence.
The data on what works for AI search optimization is striking. Research from the Princeton and Georgia Tech GEO study found that adding statistics to content improved AI visibility by 41%, and data-rich websites earned 4.3 times more AI citations than directory-style listings. Key claims and data points placed in the first 30% of content outperformed buried information because AI agents often fail to attribute material they find deeper in the page.
This created a split in the audit framework. The old checklist handled crawlability, rendering, and performance. The new requirements demanded evaluation of content positioning, citation-readiness, entity identity, and trust architecture. Sites that passed every traditional technical check could still be invisible to AI answer engines because they lacked the trust layer.
A site can score perfectly on every traditional technical audit metric and still be invisible to the AI systems that increasingly determine who gets cited.
E-E-A-T Signals Move Into Technical Territory
E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) started as a content quality concept. Google’s Quality Rater Guidelines introduced it as a framework for human evaluators, not as a set of crawlable signals. But the gap between concept and implementation has been closing fast.
A July 2026 analysis of technical SEO trends for startups found that “the strongest trends point to a more machine-readable web where identity, trust, structure, and retrieval matter more than vanity publishing volume.” E-E-A-T signals are now showing up in technical setup, not just in content tone. Author schema, organisation markup, credential references, and trust indicators have become auditable technical elements.
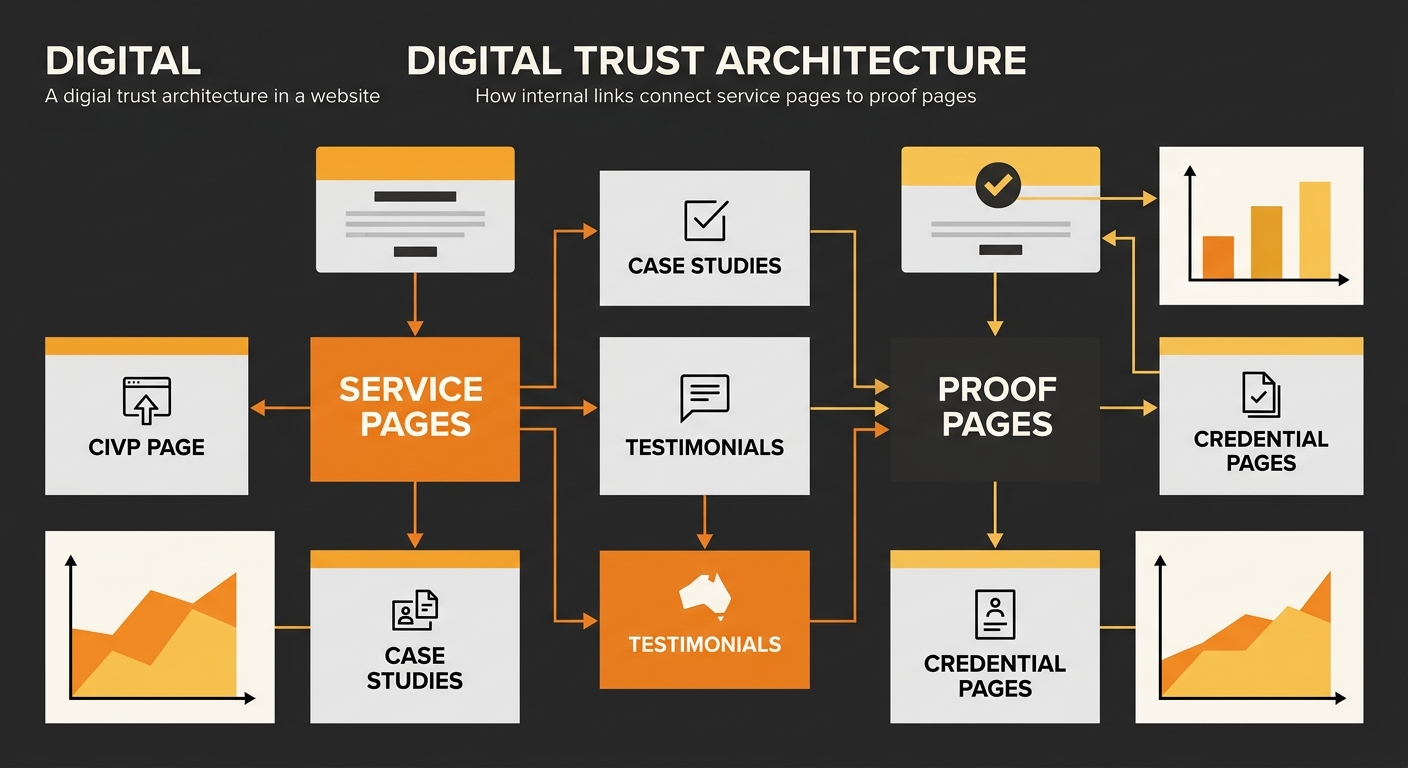
For E-E-A-T signals Australian SMEs can actually implement, the practical work breaks into three categories. First, author and organisation schema that connects content to verifiable entities. Second, internal linking that ties proof points (case studies, credentials, certifications) to the service pages they support — as KAP SEO Services notes, trust signals “should not be assumed to provide full machine-readable content without testing”. Third, topical authority architecture that demonstrates sustained expertise in a defined subject area.
That third category deserves its own attention. Topical authority compounds over time: as ClickRank’s 2026 guide documented, “each new page strengthens existing rankings instead of starting from zero,” which means random content publication actively damages the trust signal. Conductor’s research reinforces this point, showing that building topical authority requires integration of research, content creation, technical structure, and ongoing monitoring. We’ve written about how to restructure your site for AI search indexing using topic clusters, and the trust dimension is exactly why that architecture matters beyond simple navigation.
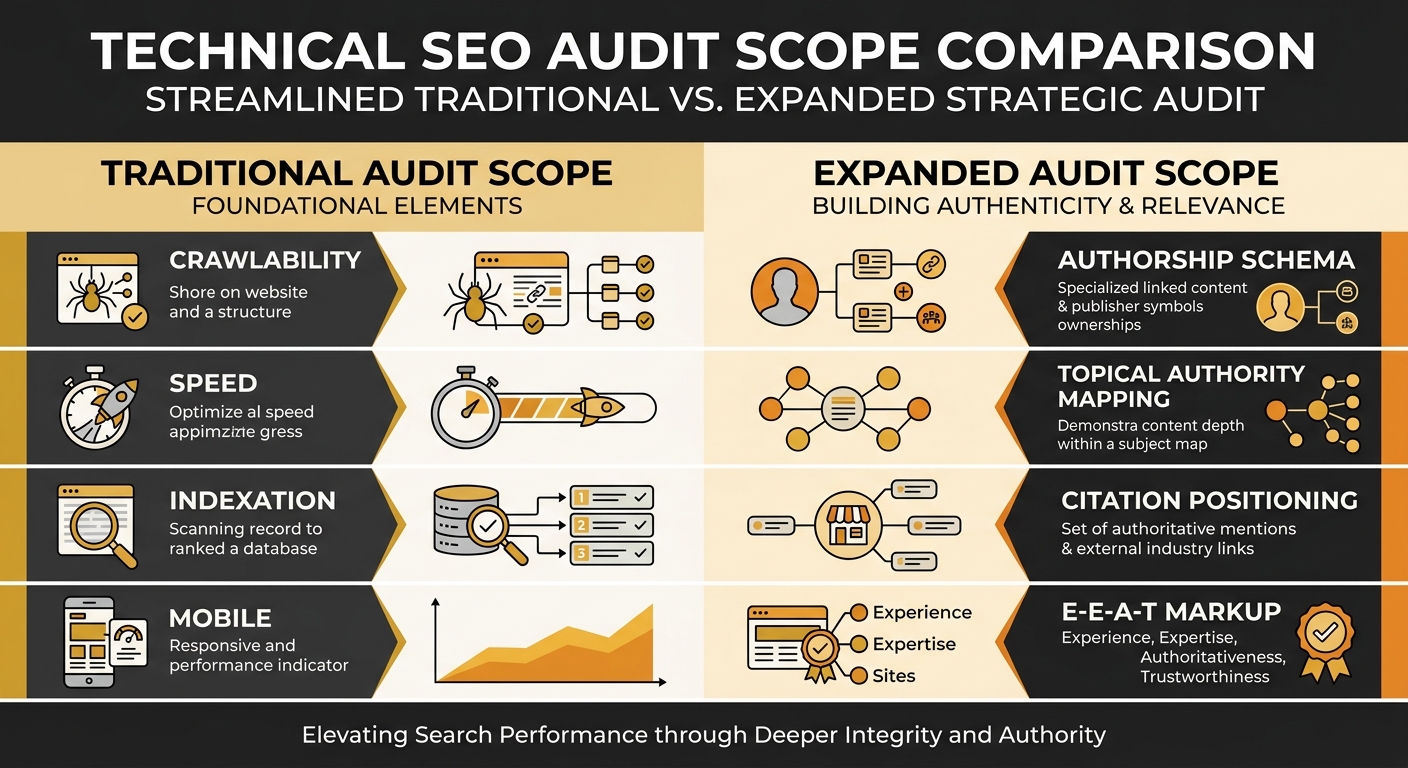
The Two-Sided Audit Framework
The trustworthy technical SEO audit that actually covers the full picture needs to evaluate both sides simultaneously. One side checks mechanical access: can search engines and AI agents crawl, render, and process the site without errors? The other side checks trust architecture: can those same systems identify who created the content, verify their credentials, and extract citable claims with confidence?
| Audit Dimension | Traditional Scope | Expanded Scope |
|---|---|---|
| Crawlability | Robots.txt, sitemap, redirect chains | AI agent access rules, crawl directives for LLM bots |
| Rendering | JavaScript rendering, mobile display | Semantic HTML structure, heading hierarchy for extraction |
| Speed | Core Web Vitals, TTFB, LCP | Load performance under AI agent crawl patterns |
| Indexation | Index status, canonical tags | Citation positioning, first-30% content placement |
| Structured Data | Basic schema presence | Author, Organisation, credential schema with entity linking |
| Trust Architecture | Not assessed | Internal link paths from proof to service pages |
| Topical Authority | Not assessed | Content cluster mapping, gap analysis, publication depth |
For ecommerce SEO specifically, the trust dimension includes product review schema, merchant identity markup, and return policy structured data — elements that traditional audits rarely evaluate but AI shopping agents actively parse.
The sites that identified and closed hidden technical SEO debt in their crawling rules gained an immediate advantage when AI systems began respecting those same directives. But fixing crawl conflicts without also building the trust layer leaves half the value on the table.
Where The Data Looks Like Today
Australian SMEs running standard 14-step technical audits are addressing the machine-readable half of the equation. The crawlability fundamentals still matter — HTTPS, clean sitemaps, working canonical tags, fast load times. Nobody should skip those steps.
But the audits that stop there are evaluating a site’s ability to be seen without evaluating its ability to be trusted. And in a search environment where AI systems cite 4.3 times more content from data-rich, well-attributed sources, that second evaluation determines whether your pages appear in the answers that increasingly replace the ten blue links.
The sites winning AI citations in Australian markets right now share a pattern: they pass the traditional technical audit and they’ve built a machine-readable trust layer on top of it. Author entities are marked up in schema. Internal links connect evidence to claims. Content clusters demonstrate sustained depth rather than scattered coverage. Key data sits in the first third of each page, positioned for extraction.
The audit template that held for fifteen years solved the access problem. The access problem is solved. The trust problem is where the next round of visibility will be won or lost, and most audit checklists haven’t caught up.